リモートデータストアの利用
4D アプリケーション上で公開された データストア は、異なるクライアントにより同時にアクセスすることができます:
- 4D リモートアプリケーションは ORDA を使っていれば、
dsコマンドでメインデータストアにアクセスできます。 この 4D リモートアプリケーションは従来のモードでもデータベースにアクセスできます。 これらのアクセスを処理するのは 4Dアプリケーションサーバー です。 - 他の 4Dアプリケーション (4Dリモート、4D Server) は、
Open datastoreコマンドを使ってリモートデータストアのセッションを開始できます。 アクセスを処理するのは HTTP REST サーバー です。 - モバイルアプリケーションを更新するための 4D for iOS または 4D for Android のクエリでアクセスできます。 アクセスを処理するのは HTTP サーバー です。
セッションの開始
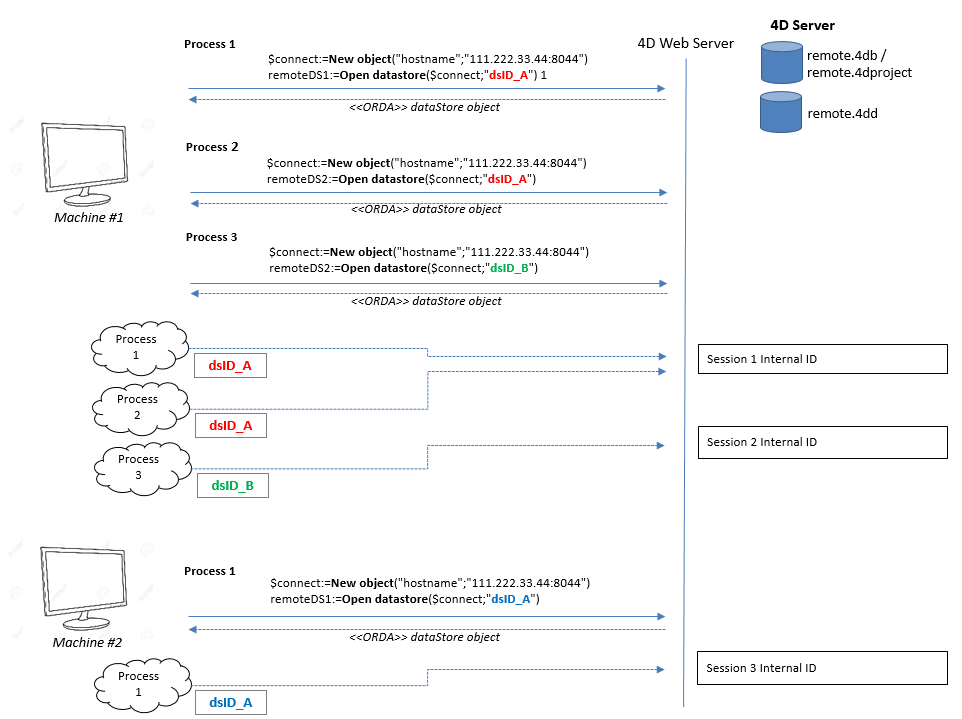
Open datastore コマンドによって参照されるリモートデータストアの場合、リクエスト元プロセスとリモートデータストア間の接続はセッションにより管理されます。
リモートデータストア上では、接続を管理するためのセッションが作成されます。 このセッションは内部的にセッションID によって識別され、4Dアプリケーション上では localID と紐づいています。 データ、エンティティセレクション、エンティティへのアクセスはこのセッションによって自動的に管理されます。
localID はリモートデータストアに接続しているマシンにおけるローカルな識別IDです:
- 同じアプリケーションの別プロセスが同じリモートデータストアに接続する場合、
localIDとセッションは共有することができます。 - 同じアプリケーションの別プロセスが別の
localIDを使って同じデータストアに接続した場合、リモートデータストアでは新しいセッションが開始されます。 - 他のマシンが同じ
localIDを使って同じデータストアに接続した場合、新しいセッションが新しい cookie で開始されます。
これらの原則を下図に示します:
REST リクエストによって開かれたセッションについては、ユーザーとセッション を参照ください。
セッションの監視
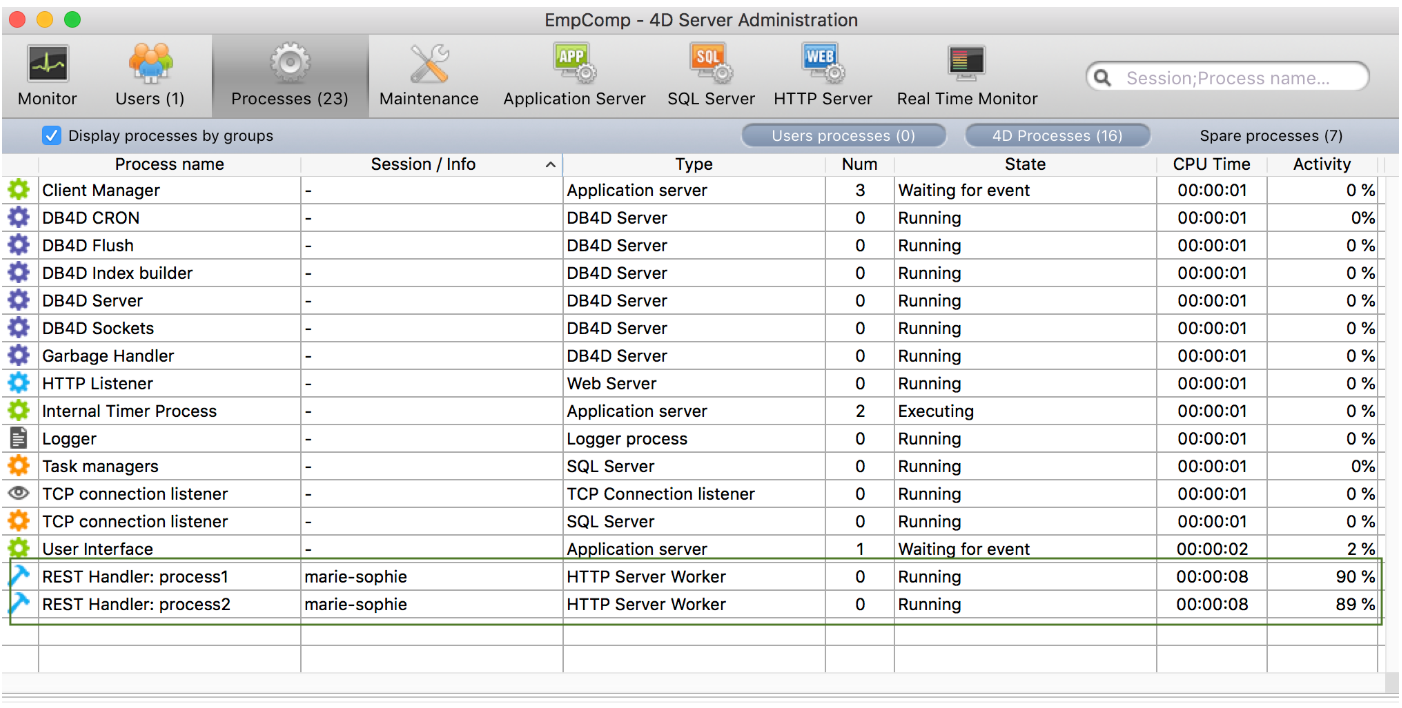
データストアアクセスを管理しているセッションは 4D Server の管理ウィンドウに表示されます:
- プロセス名: "REST Handler: <process name>"
- タイプ: HTTP Server Worker
- セッション:
Open datastoreコマンドに渡されたユーザー名
次の例では、1つのセッション上で 2つのプロセスが実行中です:
ロッキングとトランザクション
エンティティロッキングやトランザクションに関連した ORDA 機能は、ORDA のクライアント / サーバーモードと同様に、リモートデータストアにおいてもプロセスレベルで管理されます:
- あるプロセスがリモートデータストアのエンティティをロックした場合、セッションの共有如何に関わらず、他のすべてのプロセスに対してそのエンティティはロックされた状態です (エンティティロッキング 参照)。 同一のレコードに対応する複数のエンティティが 1つのプロセスによってロックされている場合、同プロセス内でそれらがすべてアンロックされないと、ロックは解除されません。 なお、ロックされたエンティティに対する参照がメモリ上に存在しなくなった場合にも、ロックは解除されます。
- トランザクションは
dataStore.startTransaction( )、dataStore.cancelTransaction( )、dataStore.validateTransaction( )のメソッドを使って、リモートデータストアごとに個別に開始・認証・キャンセルすることができます。 これらの操作は他のデータストアには影響しません。 - 従来の 4Dランゲージコマンド (
START TRANSACTION,VALIDATE TRANSACTION,CANCEL TRANSACTION) はdsで返されるメインデータストアに対してのみ動作します。 リモートデータストアのエンティティがあるプロセスのトランザクションで使われている場合、セッションの共有如何に関わらず、他のすべてのプロセスはそのエンティティを更新できません。 - 次の場合にエンティティのロックは解除され、トランザクションはキャンセルされます:
- プロセスが強制終了された
- サーバー上でセッションが閉じられた
- サーバー管理ウィンドウからセッションが強制終了された
セッションの終了
アクティビティなしにタイムアウト時間が経過すると、4D は自動的にセッションを終了します。 デフォルトのタイムアウト時間は 60分です。 Open datastore コマンドの connectionInfo パラメーターを指定して、タイムアウト時間を変更することができます。
セッション終了後にリクエストがリモートデータストアに送信された場合、セッションは可能な限り (ライセンスがあり、サーバーが停止していない、など) 再開されます。 ただしセッションが再開しても、ロックやトランザクションに関わるコンテキストは失われていることに留意が必要です (前述参照)。
クライアント/サーバーの最適化
4Dは、クライアント/サーバー環境において (ds または Open datastore によりアクセスされたデータストアの場合) エンティティセレクションを使用、あるいはエンティティを読み込む ORDAリクエストについて最適化する機構を提供しています。 この最適化機構は、ネットワーク間でやり取りされるデータの量を大幅に縮小させることで 4Dの実行速度を向上させます。 これには以下のような機能が含まれます:
- 最適化コンテキスト
- ORDAキャッシュ
コンテキスト
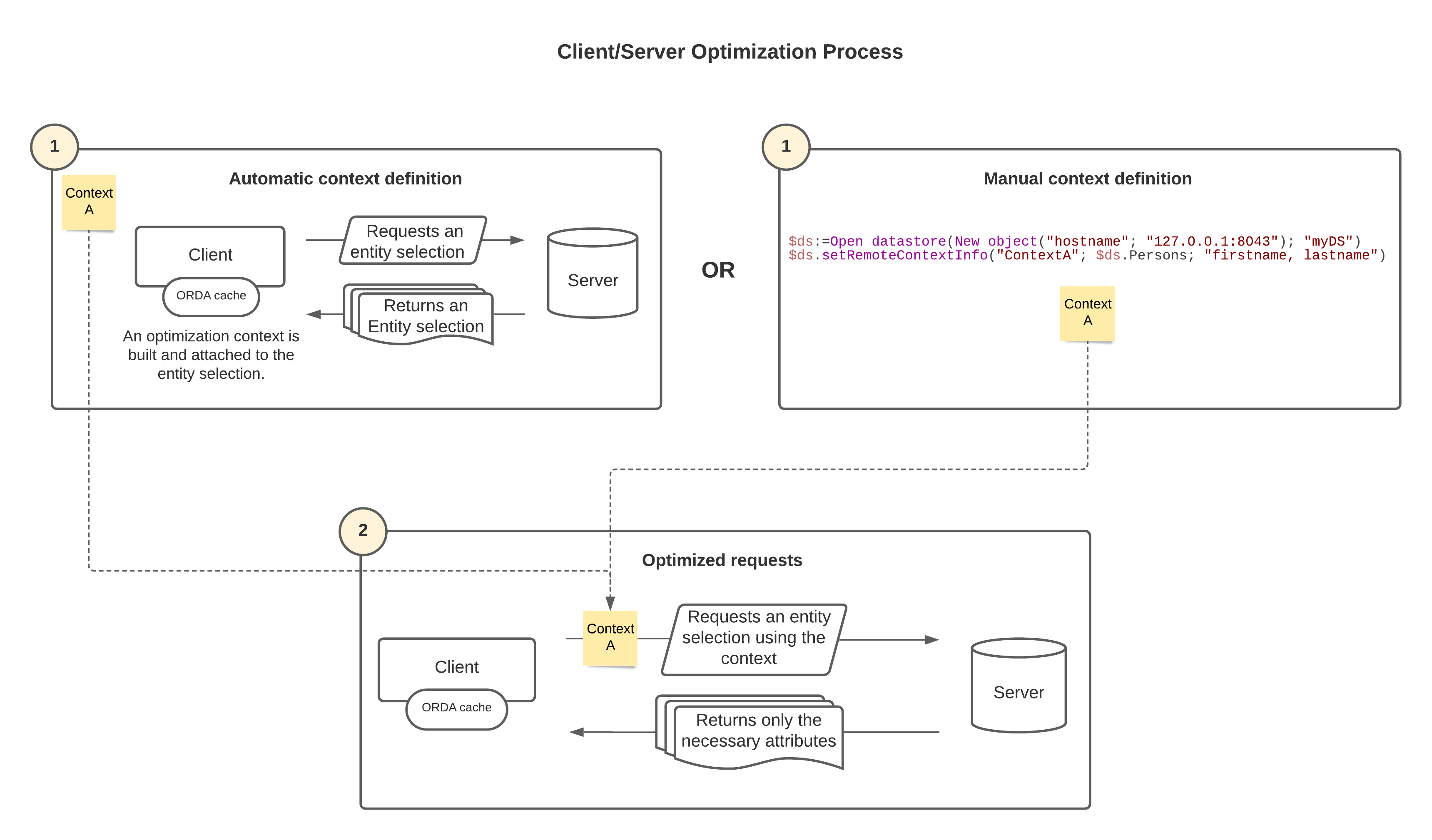
最適化コンテキストは、以下の実装に基づいています:
-
クライアントがサーバーに対してエンティティセレクションのリクエストを送ると、4D はコード実行の途中で、エンティティセレクションのどの属性がクライアント側で実際に使用されているかを自動的に "学習" し、それに対応した "最適化コンテキスト" をビルドします。 このコンテキストはエンティティセレクションに付随し、使用された属性を保存していきます。 他の属性があとで使用された場合には自動的に情報を更新していきます。 以下のメソッドや関数が学習のトリガーとなります:
-
サーバー上の同じエンティティセレクションに対してその後に送られたリクエストは、最適化コンテキストを再利用して、サーバーから必要な属性のみを取得していくことで、処理を速くします。 たとえば、エンティティセレクション型のリストボックス では、先頭行の表示中に学習がおこなわれます。 次の行からは、表示が最適化されます。 以下の関数は、ソースのエンティティセレクションの最適化コンテキストを、戻り値のエンティティセレクションに自動的に付与します:
-
既存の最適化コンテキストは、同じデータクラスの他のエンティティセレクションであればプロパティとして渡すことができるので、学習フェーズを省略して、アプリケーションをより速く実行することができます (以下の contextプロパティの使用 を参照してください)。
-
dataStore.setRemoteContextInfo()関数を使用して、最適化コンテキストを手動で構築することができます (コンテキストの事前設定 参照)。
Open datastore で確立された接続で扱われるコンテキストは、メジャーバージョンが共通する 4D でのみ使用できます。 たとえば、4D v20.x リモートアプリケーションは、4D Server v20.x のデータストアのコンテキストのみを使用できます。
例題
以下のようなコードがあるとき:
$sel:=$ds.Employee.query("firstname = ab@")
For each($e;$sel)
$s:=$e.firstname+" "+$e.lastname+" works for "+$e.employer.name // $e.employer は Company テーブルを参照します
End for each
最適化機構のおかげでこのリクエストは、ループの 2回目の繰り返しより、$sel の中で実際に使用されている属性 (firstname, lastname, employer, employer.name) のデータのみを取得するようになります。
contextプロパティの再利用
context プロパティを使用することで、最適化の利点をさらに増幅させることができます。 このプロパティは、あるエンティティセレクション用に "学習した" 最適化コンテキストを参照します。 これを新しいエンティティセレクションを返す ORDA関数に引数として渡すことで、その返されたエンティティセレクションでは学習フェーズを最初から省略して使用される属性をサーバーにリクエストできるようになります。
.setRemoteContextInfo()関数を使って、コンテキストを作成することもできます。
エンティティセレクションを扱うすべての ORDA関数は、context プロパティをサポートします (たとえば dataClass.query( ) あるいは dataClass.all( ) など)。 同じ最適化 context プロパティは、同じデータクラスのエンティティセレクションに対してであればどのエンティティセレクションにも渡すことができます。 ただし、 コードの他の部分で新しい属性が使用された際にはコンテキストは自動的に更新されるという点に注意してください。 同じコンテキストを異なるコードで再利用しすぎると、コンテキストを読み込み過ぎて、結果として効率が落ちる可能性があります。
同様の機構は読み込まれたエンティティにも実装されており、それによって使用した属性のみがリクエストされるようになります (
dataClass.get( )関数参照)。
dataClass.query( ) を使用した例:
var $sel1; $sel2; $sel3; $sel4; $querysettings; $querysettings2 : Object
var $data : Collection
$querysettings:=New object("context";"shortList")
$querysettings2:=New object("context";"longList")
$sel1:=ds.Employee.query("lastname = S@";$querysettings)
$data:=extractData($sel1) // extractData メソッド内で最適化がトリガーされ、
// コンテキスト "shortList" に紐づけられます
$sel2:=ds.Employee.query("lastname = Sm@";$querysettings)
$data:=extractData($sel2) // extractData メソッド内で最適化がトリガーされ、
// コンテキスト "shortList" に紐づけられます
$sel3:=ds.Employee.query("lastname = Smith";$querysettings2)
$data:=extractDetailedData($sel3) // extractDetailedData メソッド内で最適化がトリガーされ、
// コンテキスト "longList" に紐づけられます
$sel4:=ds.Employee.query("lastname = Brown";$querysettings2)
$data:=extractDetailedData($sel4) // extractDetailedData メソッド内で最適化がトリガーされ、
// コンテキスト "longList" に紐づけられます
エンティティセレクション型リストボックス
クライアント/サーバー環境におけるエンティティセレクション型リストボックスにおいては、そのコンテンツを表示またはスクロールする際に、最適化が自動的に適用されます。 つまり、リストボックスに表示されている属性のみがサーバーにリクエストされます。
また、リストボックスの カレントの項目 プロパティ式 (コレクション/エンティティセレクション型リストボックス 参照) を介してカレントエンティティをロードする場合には、専用の "ページモード" コンテキストが提供されます。 これによって、"ページ" が追加属性をリクエストしても、リストボックスのコンテキストのオーバーロードが避けられます。 なお、ページコンテキストの生成/使用は カレントの項目 式を使用した場合に限ります (たとえば、entitySelection[index] を介して同じエンティティにアクセスした場合は、エンティティセレクションコンテキストが変化します)。
その後、エンティティを走査する関数がサーバーに送信するリクエストにも、同じ最適化が適用されます。 以下の関数は、ソースエンティティの最適化コンテキストを、戻り値のエンティティに自動的に付与します:
たとえば、次のコードは選択したエンティティをロードし、所属しているエンティティセレクションを走査します。 エンティティは独自のコンテキストにロードされ、リストボックスのコンテキストは影響されません:
$myEntity:=Form.currentElement // カレントの項目式
//... なんらかの処理
$myEntity:=$myEntity.next() // 次のエンティティも同じコンテキストを使用してロードされます
コンテキストの事前設定
最高のパフォーマンスを得るには、アプリケーションの機能またはアルゴリズムごとに最適化コンテキストが定義されていることが推奨されます。 たとえば、あるコンテキストは顧客に関するクエリに、別のコンテキストは商品に関するクエリに使用することができます。
最高レベルに最適化された最終アプリケーションを提供したい場合、以下の手順でコンテキストを事前に設定することで、学習フェーズを省略することができます:
- アルゴリズムを設計します。
- アプリケーションを実行し、自動学習メカニズムに最適化コンテキストを作成させます。
dataStore.getRemoteContextInfo()またはdataStore.getAllRemoteContexts()関数を呼び出して、コンテキストを収集します。entitySelection.getRemoteContextAttributes()とentity.getRemoteContextAttributes()関数を使用して、アルゴリズムがどのように属性を使用するかを分析することができます。- 最後に、アプリケーション起動時に
dataStore.setRemoteContextInfo()関数を呼び出してコンテキストを構築し、これらをアルゴリズムで使用します。
ORDAキャッシュ
最適化のため、ORDA経由でサーバーにリクエストしたデータは、(4Dキャッシュとは異なる) ORDAリモートキャッシュに読み込まれます。 ORDAキャッシュはデータクラスごとに構成され、30秒後に失効します。
キャッシュに含まれるデータは、タイムアウトに達すると期限切れとみなされます。 期限切れデータにアクセスする場合は、サーバーにリクエストが送信されます。 期限切れデータは、スペースが必要になるまでキャッシュに残ります。
デフォルトでは、ORDAキャッシュは 4D によって透過的に処理されます。 しかし、以下の ORDAクラスの関数を使用して、その内容を制御することができます: